[혼공머신] 4주차: 트리 알고리즘과 앙상블

지난주 분류 알고리즘을 학습한 후, 이번 주에는 머신러닝의 또 다른 핵심인 ‘트리’ 기반 알고리즘을 다루었습니다. 데이터를 예측하고 분류하는 데 많이 활용되는 결정 트리, 모델이 얼마나 잘하는지 신뢰성 있게 평가하는 교차 검증, 그리고 모델 성능을 더욱 향상시키는 앙상블 기술까지 학습하며 머신러닝 분야에 대한 이해를 넓혔습니다.
Chapter 05 트리 알고리즘
이번 쳅터에서는 데이터를 에측하거나 분류하는 과정을 마치 ‘질문지’처럼 만들어가는 트리 기반 알고리즘의 원리를 파악했습니다. 코드를 통해 이러한 ‘질문’들이 어떻게 구성되고 왜 필요한지 명확하게 이해할 수 있었습니다.
05-1 결정 트리
결정트리는 데이터를 마치 ‘스무고개’ 하듯이 질문을 던져서 답을 찾아가는 방식입니다. 코드를 보면서 이런 질문들이 어떻게 생성되고 어떤 역할을 하는지 파악했습니다.
와인 데이터를 가지고 ‘alcohol’, ‘sugar’, ‘pH’라는 세 가지 특성을 기반으로 와인을 분류하는 문제를 해결했습니다. 데이터 준비 및 전처리 과정을 거친 후, 로지스틱 회귀 모델로 초기 성능을 확인했습니다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']]
target = wine['class']
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))이후 결정 트리 모델을 학습했습니다. 이때 모델이 공부한 데이터에 너무 딱 맞춰지면 처음 보는 데이터에는 오히려 예측이 잘 안 될 수도 있다는 것을 알게 되었습니다. 따라서 트리의 깊이(max_depth=3)를 제한하여 모델이 안정적으로 예측하도록 조절했습니다.
결정 트리가 데이터를 어떻게 나누는지 그림(plot_tree)으로도 시각적으로 쉽게 확인할 수 있었습니다. ‘alcohol’이라는 정보가 와인을 분류하는 데 가장 중요한 역할을 한다는 것도 파악했습니다.
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
plt.figure(figsize=(20, 15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
print(dt.feature_importances_)05-2 교차 검증과 그리드 서치
이번 장에서는 모델이 얼마나 잘하는지 더욱 정확하게 확인하고, 모델을 최적화하는 방법을 학습했습니다. 먼저 전체 데이터를 훈련세트(train_input)와 테스트 세트(test_input)로 분할했습니다. 이 훈련 세트를 다시 실제 모델 학습에 사용할 훈련 세트(sub_input)와 모델 검증에 사용할 검증 세트(val_input)로 나누어 활용했습니다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
sub_input, val_input, sub_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)
print(sub_input.shape, val_input.shape)새롭게 분할된 훈련 세트(sub_input)로 학습시킨 모델의 초기 성능 및 안정성을 검증 세트(val_input)로 확인 했습니다.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))모델의 실력을 더 신뢰성 있게 평가하기 위해 ‘교차 검증’ 방법을 사용했습니다. 데이터를 여러 조각으로 나누어, 돌아가면서 한 조각씩 시험용으로 사용하고 나머지는 학습용으로 활용하는 방식입니다. 이를 통해 데이터 분할 방식에 따른 편향을 줄이고 모델 성능을 안정적으로 평가할 수 있었습니다.
from sklearn.model_selection import cross_validate, StratifiedKFold
import numpy as np
scores = cross_validate(dt, train_input, train_target)
print(np.mean(scores['test_score']))
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))그리고 모델의 성능을 향상시키기 위한 ‘설정값(하이퍼파라미터)’들을 찾아주는 ‘그리드 서치’를 활용했습니다. 사용자가 직접 모든 설정값을 변경해가며 테스트할 필요 없이, GridSearchCV가 자동으로 최적의 조합을 찾아주어 편리했습니다.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(gs.best_score_)설정해야 할 파라미터가 많을 경우, ‘랜덤 서치’를 사용했습니다. 이는 랜덤으로 설정값들을 추출하여 테스트 하기 때문에 더욱 빠르고 효율적으로 최적의 설정을 찾아줄 수 있습니다.
from scipy.stats import uniform, randint
from sklearn.model_selection import RandomizedSearchCV
params = {
'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25)
}
rs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
rs.fit(train_input, train_target)
print(rs.best_params_)
print(np.max(rs.cv_results_['mean_test_score']))
dt = rs.best_estimator_
print(dt.score(test_input, test_target))05-3 트리의 앙상블
앙상블 기술은 여러 모델을 훈련하여 더 좋은 예측 결과를 만드는 머신러닝 기법입니다.
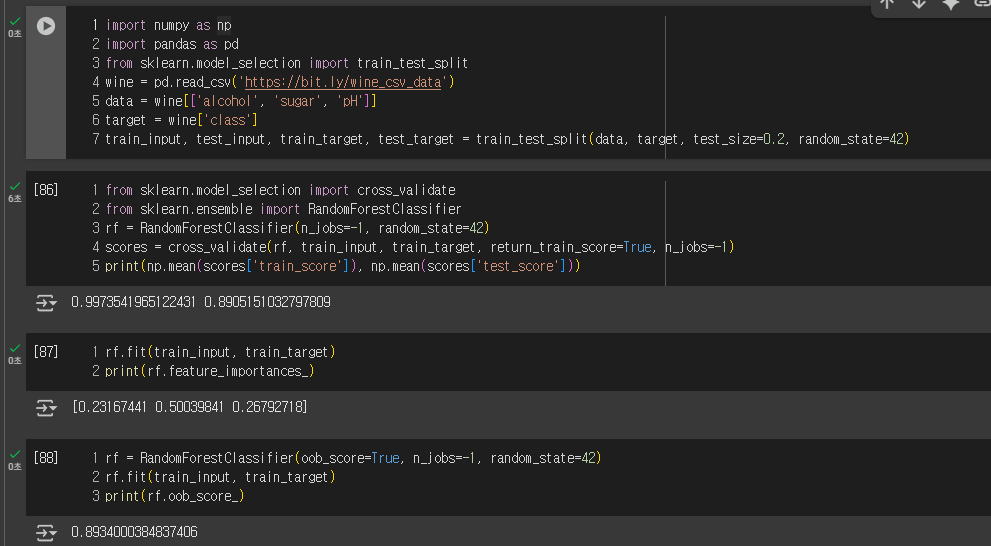
랜덤 포레스트는 결정 트리를 기반으로 하는 앙상블 방법입니다. 데이터를 무작위 샘플링(부트스트랩)하고 일부 특성만 선택해 여러 트리를 만든 뒤, 이 예측을 종합합니다.
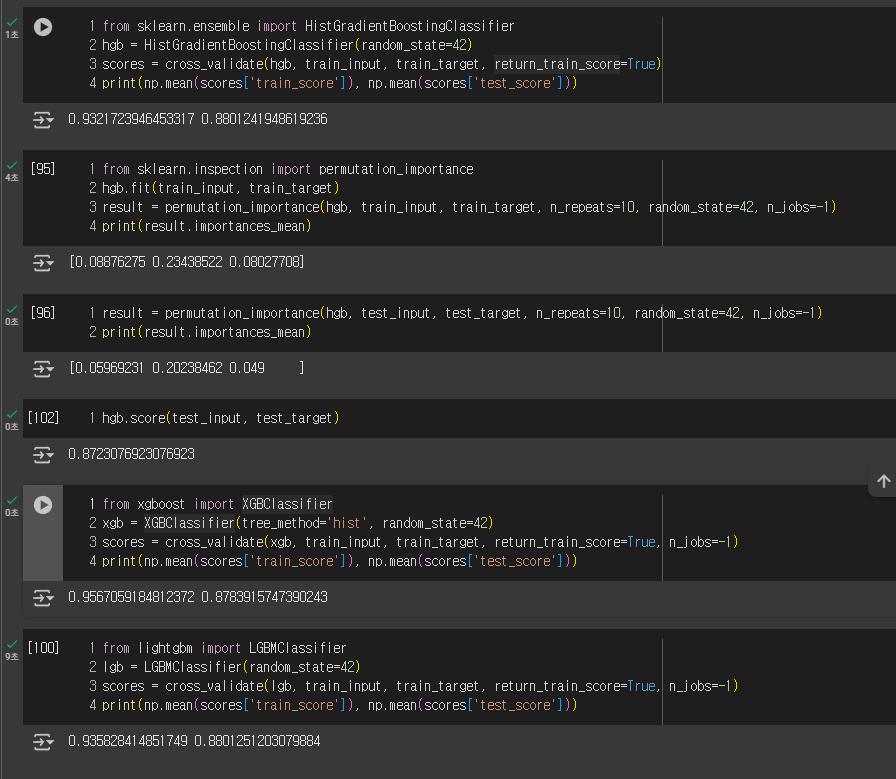
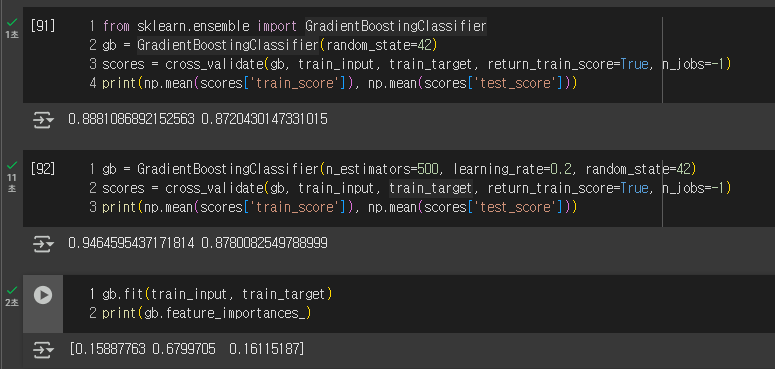
그레이디언트 부스팅은 랜덤 포레스트와 달리, 결정 트리를 순서대로 추가하여 이전 트리의 오류를 보완하며 학습하는 앙상블입니다. 손실 함수를 점진적으로 줄여나가 성능을 높입니다. 속도를 개선한 ‘히스토그램 기반 그레이디언트 부스팅’은 안정성과 높은 성능으로 인기가 많습니다.
import numpy as np
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
xgb = XGBClassifier(tree_method='hist', random_state=42)
scores = cross_validate(xgb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
lgb = LGBMClassifier(random_state=42)
scores = cross_validate(lgb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))4주차를 마치며
이번주에는 트리 모델의 기본 개념부터, 모델 실력을 공정하게 평가하고 최적의 설정값을 찾는 방법, 그리고 여러 모델을 결합하여 더 좋은 결과를 내는 과정까지 심도 있게 경험할 수 있었습니다. 모델이 작동하는 방식을 이해하고, 성능을 신뢰성 있게 확인하는 다양한 방법을 직접 익히면서 머신러닝 모델에 대한 깊이 있는 통찰을 얻는 데 큰 도움이 되었습니다.
기본 숙제(필수): 교차 검증을 그림으로 설명하기
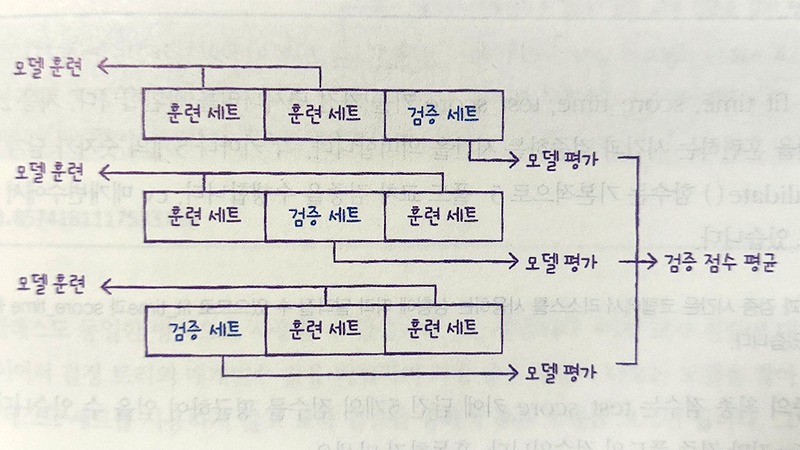
전체 데이터를 여러 조각으로 나누고, 각 조각을 한 번씩 검증 세트로 사용하고, 나머지 조각들은 훈련 세트가 됩니다.
첫 번째 줄에서는 마지막 조각을 검증 세트로, 나머지는 훈련 세트로 써소 모델을 훈련하고 평가하며, 두 번째 줄에서는 검증 세트 위치가 바뀌어 중간 조각이 검증 세트가 되고, 또 모델을 훈련하고 평가 합니다. 세 번째 줄도 마찬가지로 검증 세트가 바뀌면서 훈련과 평가를 반복합니다.
이렇게 여러 번 평가한 점수를 평균 내면, 모델이 특정 데이터에만 잘 맞는 게 아니라 전체 데이터에 대해 얼마나 안정적인지 알 수 있습니다. 한 번만 나누는 것보다 훨신 공정하고 신뢰할 수 있는 평가 방법입니다.
추가 숙제(선택): Ch.05(05-3) 앙상블 모델 손코딩(p.290 ~ 295) 코랩 화면 캡처하기
랜덤 포레스트(Random Forest)
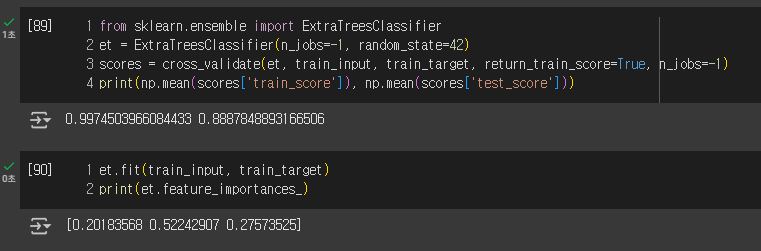
엑스트라 트리(Extra Trees)
그레이디언트 부스팅(gradient boosting)
히스토그램 기반 그레이디언트 부스팅(Histogram-based Gradient Boosting)